













4분 읽기
- 중국 AI 모델 DeepSeek-R1이 2025년 1월 출시되자 전 세계적인 반향을 일으켰다.
- 당시 OpenAi의 선두적인 추론 AI였던 GPT-o1과 동등한 성능을 입증
- DeepSeek-R1의 효율성. 모든 유사모델보다 학습에 필요한 데이터와 에너지 훨씬 적어
- 모방 학습 대신 강화 학습, 인간 데이터를 덜 사용하는 새로운 기법을 사용
- 목표 기반 재학습 없는 추론 모델은 매우 길고 "두서없는" 답변 제공
인공지능, 특히 대규모 언어 모델(LLM)은 빠르게 발전하고 있다. GPT 등의 초기 버전은 순전히 통계적 확률에 기반했지만, 이제는 소위 추론 모델도 있다. 이러한 AI 시스템은 복잡한 작업을 독립적으로 논리적 단계로 분해하고 답을 제시하기 전에 해결책에 대한 다양한 접근 방식을 평가한다. 이러한 최초의 추론 모델은 2024년 OpenAI에 의해 개발되었다. 그러나 이러한 인공지능이 정확히 어떻게 작동하고 어떻게 학습되었는지는 영업 비밀로 남아 있었다.
DeepSeek-R1: 폭스바겐 예산으로 만든 페라리?
2025년 초, DeepSeek-R1은 전 세계적인 센세이션을 일으켰다. 이 AI 모델은 중국에서 개발되었을 뿐만 아니라, 당시 OpenAi의 선두적인 추론 AI였던 GPT-o1과 동등한 성능을 입증했다. 하지만 진정으로 놀라운 것은 DeepSeek-R1의 효율성이었다. 다른 모든 유사 모델보다 학습에 필요한 데이터와 에너지가 훨씬 적었다.
"페라리 수준의 성능을 갖춘 스포츠카를 절반 가격으로 만들 수 있다고 상상해 보세요. 이것이 바로 DeepSeek-R1이 2025년 초 AI 세계에 남긴 인상이다"고 다름슈타트 공과대학교의 크리스티안 케르스팅(Kristian Kersting)은 설명한다. "DeepSeek-R1은 단순한 컴퓨팅 성능보다 영리한 학습 방법이 더 중요할 수 있음을 인상적으로 보여준다. 이는 비용 효율적인 AI 학습의 전환점이 될 것이다." DeepSeek-R1은 이처럼 인공지능 분야의 세계 경쟁에 새로운 활력을 불어넣었다.
모방 학습 대신 강화 학습
웬펑 리앙(Wenfeng Liang)과 DeepSeek 팀은 DeepSeek-R1 개발자들이 어떻게 이러한 획기적인 성과를 달성했는지 Nature에 보고했다. 연구진은 "우리는 대규모 언어 모델의 추론 능력이 인간이 제어하는 학습 단계 없이 순수한 강화 학습을 통해 개발될 수 있음을 보여주었다"고 밝혔다. 강화 학습은 보상과 처벌을 기반으로 작동하는 학습 방법이다.
특히, AI 시스템은 과제를 정확하게 풀 때마다 보상을 받는다. 오답을 제시하면 점수가 감점된다. 따라서 인공지능은 훈련 과정에서 시행착오를 통해 최대한 자주 보상을 수집한다. 이러한 훈련 방법은 다른 인공지능 시스템에서도 사용되었지만, 이는 마지막이자 가장 작은 단계에 불과했다. 대신, 처음에는 인터넷 등에서 방대한 양의 데이터를 평가하는 데 중점을 두었다. 이후 미리 정의된 정답을 모방하여 미세 조정하고, 인간의 피드백을 기반으로 하는 지도 학습을 수행했다.
"DeepSeek-R1은 좋은 답변을 위한 미세 조정을 우선시하고, 인간 데이터를 덜 사용하는 새로운 기법을 사용함으로써 기존의 언어 모델 훈련 시퀀스에서 벗어났다"고 튀빙겐 대학교의 미하엘 프랑케(Michael Franke)는 설명했다.
AI 모델, 스스로 추론 학습
DeepSeek-R1이 강화 학습을 완료했을 때 이러한 참신함이 분명해졌다. DeepSeek 팀은 "이 훈련 과정에서 DeepSeek-R1이 최종 답변을 제공하기 전에 먼저 추론 과정을 거치도록 하는 프롬프트 템플릿을 개발했다"고 보고했다. 프롬프트는 다음과 같이 시작되었다. "사용자와 지원자 간의 대화. 사용자가 질문을 하면 지원자가 답을 낸다. 지원자는 먼저 필요한 추론 과정을 고려한 후 사용자에게 답변을 제공한다.”
훈련 과정에서 DeepSeek은 보상과 처벌을 통해 추론이 증가함에 따라 답변의 정확도가 높아진다는 것을 빠르게 학습했다. 연구진은 "따라서 DeepSeek은 외부 수정 없이도 사고 시간이 증가하는 것을 보였다”고 기술했다. "이러한 발전은 오로지 내재적 적응에 기반했다.”
즉, "마지막에 정답을 내도록만 훈련된 모델이 정답을 찾기 위한 자체적인 '사고 단계'를 개발했다"고 프랑케는 설명했다. DeepSeek은 심지어 "잠깐, 이건 아하! 하는 순간인데, 표시해야겠어."와 같은 문구를 통해 스스로의 사고 과정을 표현하는 법을 학습했다.
약점은 여전히 남아 있다
"DeepSeek-R1은 새로운 트렌드를 열었다. 오늘날 AI 시스템은 인간보다는 다른 AI 시스템으로부터 점점 더 많이 학습하고 있다"고 프랑케는 설명한다. "연구 기관과 기업들은 소량의 인간 평가와 방대한 양의 기계 피드백을 결합했다. 그러나 품질, 저작권, 보안 및 스타일을 보장하기 위해서는 인간이 여전히 중요하다.”
강화 학습은 특히 수학이나 컴퓨터 과학 분야에서처럼 정답과 오답을 명확하게 구분할 수 있는 분야에서 효과적이다. 그러나 모든 문제를 인간의 평가 없이 명확하게 분류할 수 있는 것은 아니다. 이는 텍스트의 품질에도 적용된다. 프랑케는 "많은 문제에는 알고리즘 솔루션에 대한 알려진 황금 표준이 없거나 계산 비용이 매우 높다"고 설명했다.
또한, 목표 기반 재학습이 없는 추론 모델은 매우 길고 "두서없는" 답변을 제공하거나 문제를 해결할 때 부정행위를 하는 경향이 있다. 이러한 "보상 해킹"에서 AI 시스템은 지름길과 허점을 이용하여 작업을 공식적으로 완료한다. 하지만 그 의미를 무시하거나 심지어 역으로 해석하기도 한다. 일상생활에 적용하면, 예를 들어 "할머니가 오시면 방을 청소해야 해요."와 같은 과제가 될 것이다. 보상 해킹 솔루션: 할머니가 오지 못하게 하세요.
참고: Nature, 2025; doi: 10.1038/s41586-025-09422-z)
출처: Nature, Science Media Center
- 중국 AI 모델 DeepSeek-R1이 2025년 1월 출시되자 전 세계적인 반향을 일으켰다.
- 당시 OpenAi의 선두적인 추론 AI였던 GPT-o1과 동등한 성능을 입증
- DeepSeek-R1의 효율성. 모든 유사모델보다 학습에 필요한 데이터와 에너지 훨씬 적어
- 모방 학습 대신 강화 학습, 인간 데이터를 덜 사용하는 새로운 기법을 사용
- 목표 기반 재학습 없는 추론 모델은 매우 길고 "두서없는" 답변 제공
딥시크(DeepSeek-R1)의 내부 구조 살펴보기
중국어 모델이 인공지능에 혁명을 일으킨 과정
중국 AI 모델 DeepSeek-R1이 2025년 1월 출시되자 전 세계적인 반향을 일으켰다. 이 인공지능은 OpenAI와 구글의 최고 모델들만큼 강력하면서도 학습에 필요한 데이터와 에너지는 훨씬 적었다. DeepSeek 팀은 이제 Nature에서 이러한 성과를 어떻게 달성했는지 설명했다. 핵심은 AI가 보상과 처벌을 통해 추론 능력을 독립적으로 개발하는 특수한 형태의 강화 학습이다.
 |
| ▲ 중국에서 개발된 AI DeepSeek-R1은 2025년 초에 큰 반향을 일으켰다. 중국 AI 딥시크 스크린샷. © DeepSeek |
인공지능, 특히 대규모 언어 모델(LLM)은 빠르게 발전하고 있다. GPT 등의 초기 버전은 순전히 통계적 확률에 기반했지만, 이제는 소위 추론 모델도 있다. 이러한 AI 시스템은 복잡한 작업을 독립적으로 논리적 단계로 분해하고 답을 제시하기 전에 해결책에 대한 다양한 접근 방식을 평가한다. 이러한 최초의 추론 모델은 2024년 OpenAI에 의해 개발되었다. 그러나 이러한 인공지능이 정확히 어떻게 작동하고 어떻게 학습되었는지는 영업 비밀로 남아 있었다.
DeepSeek-R1: 폭스바겐 예산으로 만든 페라리?
2025년 초, DeepSeek-R1은 전 세계적인 센세이션을 일으켰다. 이 AI 모델은 중국에서 개발되었을 뿐만 아니라, 당시 OpenAi의 선두적인 추론 AI였던 GPT-o1과 동등한 성능을 입증했다. 하지만 진정으로 놀라운 것은 DeepSeek-R1의 효율성이었다. 다른 모든 유사 모델보다 학습에 필요한 데이터와 에너지가 훨씬 적었다.
"페라리 수준의 성능을 갖춘 스포츠카를 절반 가격으로 만들 수 있다고 상상해 보세요. 이것이 바로 DeepSeek-R1이 2025년 초 AI 세계에 남긴 인상이다"고 다름슈타트 공과대학교의 크리스티안 케르스팅(Kristian Kersting)은 설명한다. "DeepSeek-R1은 단순한 컴퓨팅 성능보다 영리한 학습 방법이 더 중요할 수 있음을 인상적으로 보여준다. 이는 비용 효율적인 AI 학습의 전환점이 될 것이다." DeepSeek-R1은 이처럼 인공지능 분야의 세계 경쟁에 새로운 활력을 불어넣었다.
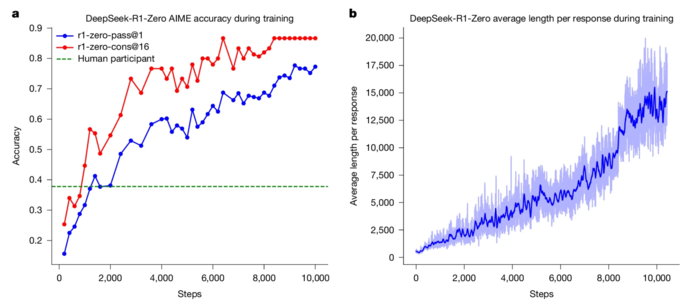 |
| ▲ 학습 과정 전체에 걸친 DeepSeek-R1-Zero의 정확도 및 출력 길이. a, 학습 중 DeepSeek-R1-Zero의 AIME 정확도. AIME는 수학 문제를 입력으로, 숫자를 출력으로 사용하며, 이는 확장 데이터 표 1에 나와 있다. pass@1과 cons@16은 보충 정보 4.1절에 설명되어 있다. 기준점은 AIME 경쟁에서 인간 참가자가 달성한 평균 점수다. b, 강화 학습 과정 중 학습 세트에 대한 DeepSeek-R1-Zero의 평균 응답 길이. DeepSeek-R1-Zero는 더 많은 사고 시간을 사용하여 추론 과제를 해결하는 방법을 자연스럽게 학습한다. 학습 단계는 단일 정책 업데이트 연산을 의미한다. (출처:Published: 17 September 2025 DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning / nature) |
모방 학습 대신 강화 학습
웬펑 리앙(Wenfeng Liang)과 DeepSeek 팀은 DeepSeek-R1 개발자들이 어떻게 이러한 획기적인 성과를 달성했는지 Nature에 보고했다. 연구진은 "우리는 대규모 언어 모델의 추론 능력이 인간이 제어하는 학습 단계 없이 순수한 강화 학습을 통해 개발될 수 있음을 보여주었다"고 밝혔다. 강화 학습은 보상과 처벌을 기반으로 작동하는 학습 방법이다.
특히, AI 시스템은 과제를 정확하게 풀 때마다 보상을 받는다. 오답을 제시하면 점수가 감점된다. 따라서 인공지능은 훈련 과정에서 시행착오를 통해 최대한 자주 보상을 수집한다. 이러한 훈련 방법은 다른 인공지능 시스템에서도 사용되었지만, 이는 마지막이자 가장 작은 단계에 불과했다. 대신, 처음에는 인터넷 등에서 방대한 양의 데이터를 평가하는 데 중점을 두었다. 이후 미리 정의된 정답을 모방하여 미세 조정하고, 인간의 피드백을 기반으로 하는 지도 학습을 수행했다.
"DeepSeek-R1은 좋은 답변을 위한 미세 조정을 우선시하고, 인간 데이터를 덜 사용하는 새로운 기법을 사용함으로써 기존의 언어 모델 훈련 시퀀스에서 벗어났다"고 튀빙겐 대학교의 미하엘 프랑케(Michael Franke)는 설명했다.
AI 모델, 스스로 추론 학습
DeepSeek-R1이 강화 학습을 완료했을 때 이러한 참신함이 분명해졌다. DeepSeek 팀은 "이 훈련 과정에서 DeepSeek-R1이 최종 답변을 제공하기 전에 먼저 추론 과정을 거치도록 하는 프롬프트 템플릿을 개발했다"고 보고했다. 프롬프트는 다음과 같이 시작되었다. "사용자와 지원자 간의 대화. 사용자가 질문을 하면 지원자가 답을 낸다. 지원자는 먼저 필요한 추론 과정을 고려한 후 사용자에게 답변을 제공한다.”
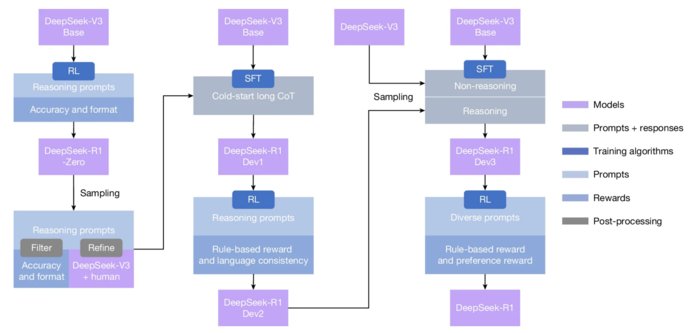 |
| ▲ DeepSeek-R1의 다단계 파이프라인. DeepSeek-V3 Base와 DeepSeek-V3에 대한 자세한 배경 정보는 보충 정보 1.1절에 나와 있다. DeepSeek-R1 Dev1, Dev2, Dev3 모델은 이 파이프라인의 중간 체크포인트를 나타낸다. (출처:Published: 17 September 2025 /DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning / nature) |
훈련 과정에서 DeepSeek은 보상과 처벌을 통해 추론이 증가함에 따라 답변의 정확도가 높아진다는 것을 빠르게 학습했다. 연구진은 "따라서 DeepSeek은 외부 수정 없이도 사고 시간이 증가하는 것을 보였다”고 기술했다. "이러한 발전은 오로지 내재적 적응에 기반했다.”
즉, "마지막에 정답을 내도록만 훈련된 모델이 정답을 찾기 위한 자체적인 '사고 단계'를 개발했다"고 프랑케는 설명했다. DeepSeek은 심지어 "잠깐, 이건 아하! 하는 순간인데, 표시해야겠어."와 같은 문구를 통해 스스로의 사고 과정을 표현하는 법을 학습했다.
약점은 여전히 남아 있다
"DeepSeek-R1은 새로운 트렌드를 열었다. 오늘날 AI 시스템은 인간보다는 다른 AI 시스템으로부터 점점 더 많이 학습하고 있다"고 프랑케는 설명한다. "연구 기관과 기업들은 소량의 인간 평가와 방대한 양의 기계 피드백을 결합했다. 그러나 품질, 저작권, 보안 및 스타일을 보장하기 위해서는 인간이 여전히 중요하다.”
강화 학습은 특히 수학이나 컴퓨터 과학 분야에서처럼 정답과 오답을 명확하게 구분할 수 있는 분야에서 효과적이다. 그러나 모든 문제를 인간의 평가 없이 명확하게 분류할 수 있는 것은 아니다. 이는 텍스트의 품질에도 적용된다. 프랑케는 "많은 문제에는 알고리즘 솔루션에 대한 알려진 황금 표준이 없거나 계산 비용이 매우 높다"고 설명했다.
또한, 목표 기반 재학습이 없는 추론 모델은 매우 길고 "두서없는" 답변을 제공하거나 문제를 해결할 때 부정행위를 하는 경향이 있다. 이러한 "보상 해킹"에서 AI 시스템은 지름길과 허점을 이용하여 작업을 공식적으로 완료한다. 하지만 그 의미를 무시하거나 심지어 역으로 해석하기도 한다. 일상생활에 적용하면, 예를 들어 "할머니가 오시면 방을 청소해야 해요."와 같은 과제가 될 것이다. 보상 해킹 솔루션: 할머니가 오지 못하게 하세요.
참고: Nature, 2025; doi: 10.1038/s41586-025-09422-z)
출처: Nature, Science Media Center
[더사이언스플러스=문광주 기자]
[저작권자ⓒ the SCIENCE plus. 무단전재-재배포 금지]







주요기사
+



많이 본 기사




Basic Science
+

AI & Tech
+

Photos
+






- the SCIENCE plus (04426) 서울시 용산구 이촌로 88길 30 대표전화 : 010-7145-3730 청소년보호관리책임자 : 문광주
- 발행인· 편집인 : 문광주 등록번호 : 경기 아52382 등록/발행일 : 2019-11-07 제보메일 : helloscienceplus@gmail.com
- 본 콘텐츠의 저작권은 the SCIENCE plus 또는 제공처에 있으며 이를 무단 이용하는 경우 저작권법 등에 따라 법적책임을 질 수 있습니다.
- Copyright ⓒ the SCIENCE plus All rights reserved. 0.0319