













5분 읽기
- AI 시스템이 인간 전문가 능력에 가까워질수록 그들의 역량, 한계 정확히 아는 것 중요
- 50개국, 대학, 연구센터, 과학 기관의 천 명이 넘는 과학자들 도움으로 테스트 개발
- AI중 어느 것도 테스트에서 10% 이상 달성 못해.모두 확신 가지고 틀린 답 내놓아
- AI 모델 2025년 말까지 마지막 시험 문제의 50% 이상 정확하게 풀 수 있을 것으로 예상
인공지능은 급속히 발전하고 있으며, 특히 대규모 언어 모델(LLM)의 기능은 계속해서 엄청난 진전을 이루고 있다. 최근 들어 OpenAI-o1, DeepSeek-R1과 같은 새로운 추론 모델이 큰 인기를 얻고 있다. 이러한 AI 시스템은 복잡한 작업을 논리적인 단계로 나누고, 답을 공식화하기 전에 이를 해결하기 위한 다양한 접근 방식을 검토한다. 환각, 비이성적 오류, 고의적 거짓말과 같은 문제가 여전히 남아 있기는 하지만, 오늘날의 최고 언어 모델은 약 2년 전만 해도 정말 어려워했는데 이제는 쉽게 문제없이 테스트를 통과했다.
"AI 시스템이 인간 전문가의 성과에 가까워질수록 그들의 역량과 한계를 정확히 아는 것이 더욱 중요해진다"고 AI Safety 센터의 댄 헨드릭스(Dan Hendrycks)와 Scale AI의 서머 웨(Summer Yue)가 이끄는 팀이 설명했다. 그러나 현재 벤치마크는 이와 관련해 대부분 가능성을 이용했으며 최신 AI 모델은 90% 이상을 달성했다. "이로 인해 AI 성능을 정확하게 측정하는 능력이 제한되고 대규모 언어 모델의 빠른 진행 상황을 포착할 수 있는 더 정교한 테스트가 필요하다"고 Hendrycks와 그의 팀은 말했다.
인류의 마지막 시험
AI 연구자들은 이제 50개국에 있는 대학, 연구 센터 및 기타 과학 기관의 천 명이 넘는 과학자들의 도움을 받아 이러한 테스트를 개발했다. "인류의 마지막 시험"이라 불리는 이 시험에는 수학과 물리학부터 의학, 화학, 컴퓨터 과학, 언어학과 인문학까지 100개 분야에서 3천 개의 문제가 포함되어 있다.
"이 시험에는 가장 어렵고 다양하며 다중 모드의 문제 3천 개가 포함되어 있으며 AI를 위한 이런 종류의 궁극적인 학업 시험이 되도록 고안되었다"고 팀은 설명했다. 이러한 문제는 단순히 인터넷 검색이나 훈련 데이터 보기만으로는 풀 수 없도록 설계되었다. 질문의 80%는 구체적이고 자동으로 검증 가능한 답변을 요구하고, 일부는 객관식 질문이다. 약 10%의 업무는 다중 모드이며, 예를 들어 이미지나 다이어그램을 평가해야 한다. Scale AI는 "마지막 시험은 수학 문제에서 추론하는 능력과 다양한 과목 영역에 대한 지식의 폭을 모두 테스트하도록 설계되었다"고 원리를 설명했다.
DeepSeek, GPT-o1 등에게는 너무 어렵다.
한편, OpenAI-o1, Gemini 2.0 Flash Thinking, DeepSeek R1, Llama 및 Qwen의 최고 모델을 포함하여 여러 최고 언어 모델이 이 "마지막 시험"을 통과했다.
결과:
이들 인공지능 중 어느 것도 테스트에서 10% 이상을 달성하지 못했다. 멀티모달 모드에서 가장 좋은 결과는 OpenAI-o1이 9.07%로 달성했고, 텍스트 기반 모드에서는 DeepSeek-R1이 9.35%로 앞서 나갔다. 제미니 2.0은 멀티모달 모드에서 7.67%를 달성했고, 라마와 웬은 각각 5% 안팎을 기록했다.
"대부분 AI 모델은 마지막 시험에서 어려움을 겪지만, 추론 모델은 이러한 기술이 없는 모델보다 약간 더 나은 성과를 보이는 경향이 있다"고 Hendrycks와 그의 팀이 보고했다. "이러한 제한적인 성공은 부분적으로 다음과 같은 이유에서 비롯된다. 질문을 선택할 때, 우리는 일반적인 AI 모델이 처음부터 올바르게 답할 수 있는 질문을 제외했다.“
틀린 답변에도 불구하고 높은 자신감
또한, 테스트한 AI 시스템 모두 확신을 가지고 틀린 답을 내놓았고, 신뢰도를 높게 평가했다는 점이 인상적이었다. 정확성과 자기평가 사이의 이러한 불일치는 인공지능의 보정이 제대로 되지 않았다는 신호로 간주된다. Scale AI는 "잘 교정된 시스템의 경우 벤치마크의 정확성과 신뢰도는 거의 같아야 한다"고 설명했다. 그러니까 적중률이 50% 정도라면 AI도 자신의 성과를 이 정도로 추정할 것이다.
하지만 "마지막 시험"에서는 상황이 달랐다. AI 모델은 답변의 신뢰도를 80% 이상으로 추정했지만, 작업의 10% 미만에서만 정답을 맞혔다. 헨드릭스와 그의 팀은 "그들은 작업이 자신의 능력을 초과할 때 이를 인식하지 못한다"고 썼다. 이러한 오차는 환각과 모델 조작의 강력한 증거로 간주된다.
그 다음에는 무슨 일이 일어날까?
DeepSeek, OpenAI-o1 등이 지금까지 '인류의 마지막 시험'에서 다소 부진한 성적을 보였지만 이런 상황이 오래 지속되진 않을 것이다. AI 연구자들은 "인공지능의 급속한 발전을 감안할 때, AI 모델이 2025년 말까지 마지막 시험 문제의 50% 이상을 정확하게 풀 수 있을 것으로 예상한다"고 예측했다. 끊임없이 진화하는 AI 시험에서 좋은 성과를 거두는 것은 AI 시스템이 과학적 지식 면에서 인간 전문가와 경쟁할 수 있다는 신호가 될 것이다.
그러나 그것만으로는 "인공 일반 지능(AGI)"의 징후가 될 수 없다. 즉, 모든 면에서 우리 인간과 동등하거나 더 우수한 AI이다. 우리의 테스트에는 구조화된 학문적 문제가 포함되어 있으므로 기술 지식과 AI 연구자들은 "추론은 개방형 연구나 창의적인 문제 해결 기술에는 덜 중요하다"고 기록했다. "마지막 시험이 AI 모델에 대한 마지막 학업 시험이기는 하지만, 인공지능에 대한 마지막 벤치마크는 결코 아니다.“
하지만 AI 연구자들은 '인류의 마지막 시험'을 인공지능의 발전과 잠재적 위험을 더욱 잘 평가하기 위한 중요한 벤치마크로 보고 있다. 특히 필요한 규제와 제한을 결정하기 위해서는 이것이 중요하다.
(arxiV Preprint, 2025; doi: 10.48550/arXiv.2501.14249)
출처: Scale AI, Center für AI Safety
- AI 시스템이 인간 전문가 능력에 가까워질수록 그들의 역량, 한계 정확히 아는 것 중요
- 50개국, 대학, 연구센터, 과학 기관의 천 명이 넘는 과학자들 도움으로 테스트 개발
- AI중 어느 것도 테스트에서 10% 이상 달성 못해.모두 확신 가지고 틀린 답 내놓아
- AI 모델 2025년 말까지 마지막 시험 문제의 50% 이상 정확하게 풀 수 있을 것으로 예상
DeepSeek와 유사 대규모 AI모델들, "마지막 시험"에 실패
최고의 인공지능도 한계에 도전하는 궁극적인 테스트
"인류의 마지막 시험 Humanity’s Last Exam":
AI 연구자들은 현재 최고의 AI 모델조차도 실패하는 새로운 시험을 개발했다. DeepSeek, OpenAI-o1, Gemini 2.0과 같은 대규모 언어 모델은 3천 개의 작업 중 10% 미만만 올바르게 해결했고, 대부분은 5% 정도만 달성했다. 그러므로 인간은 적어도 전문가 수준의 과학에서는 여전히 앞서 있다. "마지막 시험"의 문제는 100개 이상의 과목 분야에서 나왔으며 전 세계 연구자들이 제출했다.
 |
| ▲ 가장 뛰어난 AI 모델조차도 새로운 시험인 "인류의 마지막 시험"에 실패했다. © PhonlamaiPjoto/ Getty 이미지 |
인공지능은 급속히 발전하고 있으며, 특히 대규모 언어 모델(LLM)의 기능은 계속해서 엄청난 진전을 이루고 있다. 최근 들어 OpenAI-o1, DeepSeek-R1과 같은 새로운 추론 모델이 큰 인기를 얻고 있다. 이러한 AI 시스템은 복잡한 작업을 논리적인 단계로 나누고, 답을 공식화하기 전에 이를 해결하기 위한 다양한 접근 방식을 검토한다. 환각, 비이성적 오류, 고의적 거짓말과 같은 문제가 여전히 남아 있기는 하지만, 오늘날의 최고 언어 모델은 약 2년 전만 해도 정말 어려워했는데 이제는 쉽게 문제없이 테스트를 통과했다.
"AI 시스템이 인간 전문가의 성과에 가까워질수록 그들의 역량과 한계를 정확히 아는 것이 더욱 중요해진다"고 AI Safety 센터의 댄 헨드릭스(Dan Hendrycks)와 Scale AI의 서머 웨(Summer Yue)가 이끄는 팀이 설명했다. 그러나 현재 벤치마크는 이와 관련해 대부분 가능성을 이용했으며 최신 AI 모델은 90% 이상을 달성했다. "이로 인해 AI 성능을 정확하게 측정하는 능력이 제한되고 대규모 언어 모델의 빠른 진행 상황을 포착할 수 있는 더 정교한 테스트가 필요하다"고 Hendrycks와 그의 팀은 말했다.
 |
| ▲ "인류 마지막 시험"에 대한 다양한 과학 분야별 분포 © Phan et al./arxiV, 2025; CC-by 4.0 |
인류의 마지막 시험
AI 연구자들은 이제 50개국에 있는 대학, 연구 센터 및 기타 과학 기관의 천 명이 넘는 과학자들의 도움을 받아 이러한 테스트를 개발했다. "인류의 마지막 시험"이라 불리는 이 시험에는 수학과 물리학부터 의학, 화학, 컴퓨터 과학, 언어학과 인문학까지 100개 분야에서 3천 개의 문제가 포함되어 있다.
"이 시험에는 가장 어렵고 다양하며 다중 모드의 문제 3천 개가 포함되어 있으며 AI를 위한 이런 종류의 궁극적인 학업 시험이 되도록 고안되었다"고 팀은 설명했다. 이러한 문제는 단순히 인터넷 검색이나 훈련 데이터 보기만으로는 풀 수 없도록 설계되었다. 질문의 80%는 구체적이고 자동으로 검증 가능한 답변을 요구하고, 일부는 객관식 질문이다. 약 10%의 업무는 다중 모드이며, 예를 들어 이미지나 다이어그램을 평가해야 한다. Scale AI는 "마지막 시험은 수학 문제에서 추론하는 능력과 다양한 과목 영역에 대한 지식의 폭을 모두 테스트하도록 설계되었다"고 원리를 설명했다.
 |
| ▲ 마지막 시험의 과제 예시. © Phan et al./arxiV, 2025; CC-by 4.0 |
DeepSeek, GPT-o1 등에게는 너무 어렵다.
한편, OpenAI-o1, Gemini 2.0 Flash Thinking, DeepSeek R1, Llama 및 Qwen의 최고 모델을 포함하여 여러 최고 언어 모델이 이 "마지막 시험"을 통과했다.
결과:
이들 인공지능 중 어느 것도 테스트에서 10% 이상을 달성하지 못했다. 멀티모달 모드에서 가장 좋은 결과는 OpenAI-o1이 9.07%로 달성했고, 텍스트 기반 모드에서는 DeepSeek-R1이 9.35%로 앞서 나갔다. 제미니 2.0은 멀티모달 모드에서 7.67%를 달성했고, 라마와 웬은 각각 5% 안팎을 기록했다.
"대부분 AI 모델은 마지막 시험에서 어려움을 겪지만, 추론 모델은 이러한 기술이 없는 모델보다 약간 더 나은 성과를 보이는 경향이 있다"고 Hendrycks와 그의 팀이 보고했다. "이러한 제한적인 성공은 부분적으로 다음과 같은 이유에서 비롯된다. 질문을 선택할 때, 우리는 일반적인 AI 모델이 처음부터 올바르게 답할 수 있는 질문을 제외했다.“
틀린 답변에도 불구하고 높은 자신감
또한, 테스트한 AI 시스템 모두 확신을 가지고 틀린 답을 내놓았고, 신뢰도를 높게 평가했다는 점이 인상적이었다. 정확성과 자기평가 사이의 이러한 불일치는 인공지능의 보정이 제대로 되지 않았다는 신호로 간주된다. Scale AI는 "잘 교정된 시스템의 경우 벤치마크의 정확성과 신뢰도는 거의 같아야 한다"고 설명했다. 그러니까 적중률이 50% 정도라면 AI도 자신의 성과를 이 정도로 추정할 것이다.
하지만 "마지막 시험"에서는 상황이 달랐다. AI 모델은 답변의 신뢰도를 80% 이상으로 추정했지만, 작업의 10% 미만에서만 정답을 맞혔다. 헨드릭스와 그의 팀은 "그들은 작업이 자신의 능력을 초과할 때 이를 인식하지 못한다"고 썼다. 이러한 오차는 환각과 모델 조작의 강력한 증거로 간주된다.
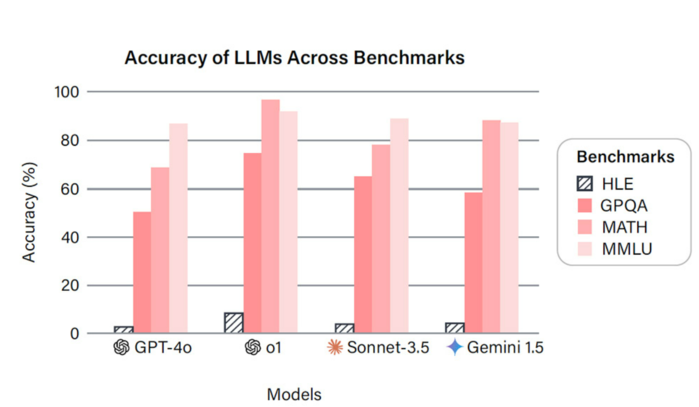 |
| ▲ 기존 벤치마크와 최종 시험(HLE)에서 일부 대규모 언어 모델의 성능. © Phan et al./arxiV, 2025; CC-by 4.0 |
그 다음에는 무슨 일이 일어날까?
DeepSeek, OpenAI-o1 등이 지금까지 '인류의 마지막 시험'에서 다소 부진한 성적을 보였지만 이런 상황이 오래 지속되진 않을 것이다. AI 연구자들은 "인공지능의 급속한 발전을 감안할 때, AI 모델이 2025년 말까지 마지막 시험 문제의 50% 이상을 정확하게 풀 수 있을 것으로 예상한다"고 예측했다. 끊임없이 진화하는 AI 시험에서 좋은 성과를 거두는 것은 AI 시스템이 과학적 지식 면에서 인간 전문가와 경쟁할 수 있다는 신호가 될 것이다.
그러나 그것만으로는 "인공 일반 지능(AGI)"의 징후가 될 수 없다. 즉, 모든 면에서 우리 인간과 동등하거나 더 우수한 AI이다. 우리의 테스트에는 구조화된 학문적 문제가 포함되어 있으므로 기술 지식과 AI 연구자들은 "추론은 개방형 연구나 창의적인 문제 해결 기술에는 덜 중요하다"고 기록했다. "마지막 시험이 AI 모델에 대한 마지막 학업 시험이기는 하지만, 인공지능에 대한 마지막 벤치마크는 결코 아니다.“
하지만 AI 연구자들은 '인류의 마지막 시험'을 인공지능의 발전과 잠재적 위험을 더욱 잘 평가하기 위한 중요한 벤치마크로 보고 있다. 특히 필요한 규제와 제한을 결정하기 위해서는 이것이 중요하다.
(arxiV Preprint, 2025; doi: 10.48550/arXiv.2501.14249)
출처: Scale AI, Center für AI Safety
[더사이언스플러스=문광주 기자]
[저작권자ⓒ the SCIENCE plus. 무단전재-재배포 금지]







주요기사
+



많이 본 기사




Basic Science
+

AI & Tech
+

Photos
+






- the SCIENCE plus (04426) 서울시 용산구 이촌로 88길 30 대표전화 : 010-7145-3730 청소년보호관리책임자 : 문광주
- 발행인· 편집인 : 문광주 등록번호 : 경기 아52382 등록/발행일 : 2019-11-07 제보메일 : helloscienceplus@gmail.com
- 본 콘텐츠의 저작권은 the SCIENCE plus 또는 제공처에 있으며 이를 무단 이용하는 경우 저작권법 등에 따라 법적책임을 질 수 있습니다.
- Copyright ⓒ the SCIENCE plus All rights reserved. 0.0829