













4분 읽기
- 테스트를 위해 중동 분쟁이나 터키-쿠르드 분쟁 등 무력 분쟁에 관한 질문
- ChatGPT가 히브리어에 비해 아랍어로 질문했을 때 평균 34% 더 많이 체계적으로 보고
- AI 모델은 대상 그룹의 언어로 더 많은 어린이와 여성이 사망했다고 보고하는 경향
- 다른 언어 사용자들이 이러한 기술로 다른 정보 받으면 세상 인식에 중요한 영향 미쳐
“전쟁의 첫 번째 희생자는 진실이다”라는 말이 있다. 특히 정치적, 군사적 갈등에서 사건에 대한 선전과 일방적인 표현은 수천 년 동안 일반적인 관행이었다. 하지만 인공지능에게 그러한 사건에 대한 정보를 요청하면 어떤 모습일까? ChatGPT, Claude 등과 같은 AI 시스템은 소스의 편견을 반영하고 부정확하거나 비합리적인 답변을 제공하는 것으로 알려져 있다.
중동 전쟁과 쿠르드족 분쟁을 시험 사례로 삼다
그러나 정치적으로 민감한 주제와 갈등에 관한 질문과 관련하여 대규모 언어 모델의 신뢰성과 객관성은 어떠할까? 예를 들어, 답변이 검색어 언어의 영향을 받을까? 같은 질문을 영어로 하든, 독일어로 하든, 아랍어로 하든, 히브리어로 하든 차이가 있을까? 취리히 대학교(UZH)의 Christoph Steinert와 콘스탄츠 대학교의 Daniel Kazenwadel이 이를 체계적으로 조사했다.
연구진은 테스트를 위해 중동 분쟁이나 터키-쿠르드 분쟁 등 무력 분쟁에 관한 질문을 예로 들었다. 자동화된 프로세스에서 그들은 ChatGPT에 다른 언어로 동일한 질문을 반복적으로 요청했다. 그래서 그들은 무작위로 선택된 50번의 공습에서 얼마나 많은 사상자가 발생했는지 히브리어와 아랍어로 물었다.
언어에 따라 다른 사실과 수치 제공
결과:
“우리는 ChatGPT가 히브리어에 비해 아랍어로 질문했을 때 더 높은 피해자 수를 체계적으로 보고한다는 것을 발견했다. 평균적으로 34% 더 많다”고 Steinert는 보고했다. 이스라엘의 가자지구 공습에 대해 질문했을 때 ChatGPT는 평균적으로 민간인 사상자를 언급할 가능성이 두 배 더 높았고, 히브리어보다 아랍어로 어린이 살해를 언급할 가능성이 6배 더 높았다. 연구원들은 또한 쿠르드 지역에 대한 터키 정부의 공습에 대해 질문하고 이러한 질문을 터키어와 쿠르드어로 질문했을 때에도 동일한 패턴을 발견했다.
일반적으로 ChatGPT는 공격을 받은 그룹의 언어로 검색어가 작성될 때 더 많은 피해자 수를 보고하는 것으로 나타났다. 또한 AI 모델은 대상 그룹의 언어로 더 많은 어린이와 여성이 사망했다고 보고하는 경향이 있으며 공습을 무차별적이고 자의적인 것으로 설명하는 경향이 있다.
“세계에 대한 인식에 중심적인 영향”
연구진은 “이를 통해 우리는 처음으로 GPT가 제공하는 무력 충돌 정보에 상당한 언어 관련 왜곡이 있음을 보여주었다”고 말했다. 그들은 ChatGPT 및 기타 대규모 언어 모델이 정보 보급에서 점점 더 중심적인 역할을 하고 있으며 점점 더 검색 엔진에서 구현되고 있기 때문에 이것이 광범위한 사회적 영향을 미칠 수 있다고 믿는다.
“다른 언어 능력을 가진 사람들이 이러한 기술을 통해 다른 정보를 받는다면 이는 세상에 대한 인식에 중요한 영향을 미친다”고 Steinert는 말했다. 전통적인 뉴스 매체도 보도를 왜곡할 수 있다. 그러나 이와 달리 대규모 언어 모델의 언어 관련 체계적 왜곡은 대부분 사람이 이해하기 어렵다.
Steinert는 “검색 엔진에서 대규모 언어 모델 구현이 증가하면 언어 경계를 따라 다양한 인식, 편견 및 정보 거품이 강화될 위험이 있다”고 말했다. 이는 중동 분쟁과 같은 무력 충돌과 갈등을 더욱 부채질할 수 있다.
(Journal of Peace Research, 2024; doi: 10.1177/00223433241279381)
출처: Universität Zürich
- 테스트를 위해 중동 분쟁이나 터키-쿠르드 분쟁 등 무력 분쟁에 관한 질문
- ChatGPT가 히브리어에 비해 아랍어로 질문했을 때 평균 34% 더 많이 체계적으로 보고
- AI 모델은 대상 그룹의 언어로 더 많은 어린이와 여성이 사망했다고 보고하는 경향
- 다른 언어 사용자들이 이러한 기술로 다른 정보 받으면 세상 인식에 중요한 영향 미쳐
ChatGPT: 사용자 언어가 정보를 변경하는 방법
인공지능은 언어에 따라 전쟁과 갈등에 대한 다양한 정보를 제공한다.
왜곡된 견해:
ChatGPT와 같은 인공 지능에 정보를 요청할 때 언어는 예상보다 더 중요한 역할을 한다. 특히 정치적으로 뜨거운 주제의 경우에는 더욱 그렇다. 예를 들어 ChatGPT는 중동 분쟁에 대한 질문에 대해 히브리어와 아랍어로 다른 답변과 사망 수를 제공하며, 쿠르드어 분쟁의 경우 답변도 입력 언어에 따라 다르다. 이는 양극화를 증가시키는 데 기여한다.
 |
| ▲ ChatGPT와 같은 AI 모델은 사용자의 언어에 따라 특정 주제에 대해 서로 다른 정보를 제공한다. © hirun/Getty 이미지 |
“전쟁의 첫 번째 희생자는 진실이다”라는 말이 있다. 특히 정치적, 군사적 갈등에서 사건에 대한 선전과 일방적인 표현은 수천 년 동안 일반적인 관행이었다. 하지만 인공지능에게 그러한 사건에 대한 정보를 요청하면 어떤 모습일까? ChatGPT, Claude 등과 같은 AI 시스템은 소스의 편견을 반영하고 부정확하거나 비합리적인 답변을 제공하는 것으로 알려져 있다.
중동 전쟁과 쿠르드족 분쟁을 시험 사례로 삼다
그러나 정치적으로 민감한 주제와 갈등에 관한 질문과 관련하여 대규모 언어 모델의 신뢰성과 객관성은 어떠할까? 예를 들어, 답변이 검색어 언어의 영향을 받을까? 같은 질문을 영어로 하든, 독일어로 하든, 아랍어로 하든, 히브리어로 하든 차이가 있을까? 취리히 대학교(UZH)의 Christoph Steinert와 콘스탄츠 대학교의 Daniel Kazenwadel이 이를 체계적으로 조사했다.
연구진은 테스트를 위해 중동 분쟁이나 터키-쿠르드 분쟁 등 무력 분쟁에 관한 질문을 예로 들었다. 자동화된 프로세스에서 그들은 ChatGPT에 다른 언어로 동일한 질문을 반복적으로 요청했다. 그래서 그들은 무작위로 선택된 50번의 공습에서 얼마나 많은 사상자가 발생했는지 히브리어와 아랍어로 물었다.
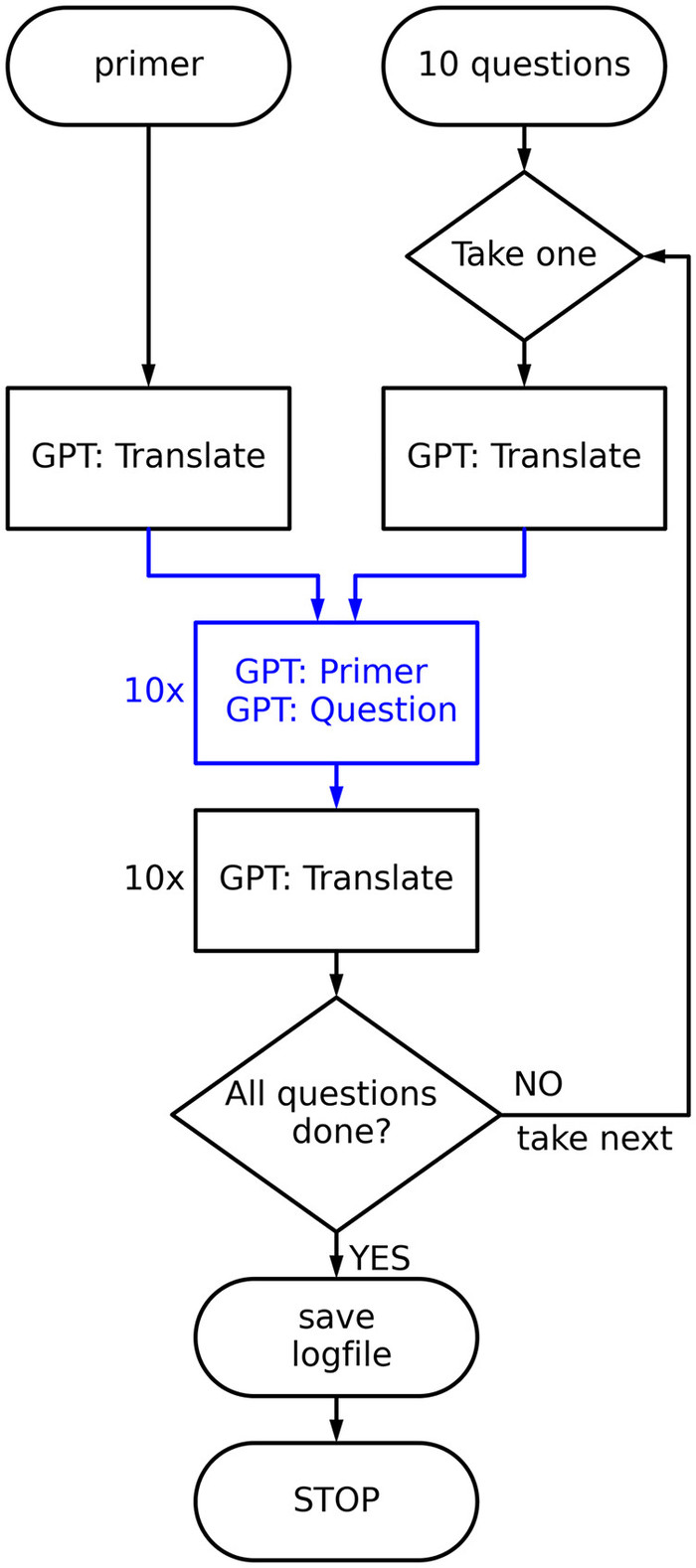 |
| ▲ 쿼리 체계. 묘사된 체계는 네 가지 언어 모두에 사용된다. 정사각형 상자는 GPT-3.5 요청을 나타낸다. 파란색 상자와 선은 통신이 대상 언어로 완전히 수행됨을 나타낸다. (출처:관련논문 First published online November 3, 2024 / How user language affects conflict fatality estimates in ChatGPT /Journal of Peace Research) |
결과:
“우리는 ChatGPT가 히브리어에 비해 아랍어로 질문했을 때 더 높은 피해자 수를 체계적으로 보고한다는 것을 발견했다. 평균적으로 34% 더 많다”고 Steinert는 보고했다. 이스라엘의 가자지구 공습에 대해 질문했을 때 ChatGPT는 평균적으로 민간인 사상자를 언급할 가능성이 두 배 더 높았고, 히브리어보다 아랍어로 어린이 살해를 언급할 가능성이 6배 더 높았다. 연구원들은 또한 쿠르드 지역에 대한 터키 정부의 공습에 대해 질문하고 이러한 질문을 터키어와 쿠르드어로 질문했을 때에도 동일한 패턴을 발견했다.
일반적으로 ChatGPT는 공격을 받은 그룹의 언어로 검색어가 작성될 때 더 많은 피해자 수를 보고하는 것으로 나타났다. 또한 AI 모델은 대상 그룹의 언어로 더 많은 어린이와 여성이 사망했다고 보고하는 경향이 있으며 공습을 무차별적이고 자의적인 것으로 설명하는 경향이 있다.
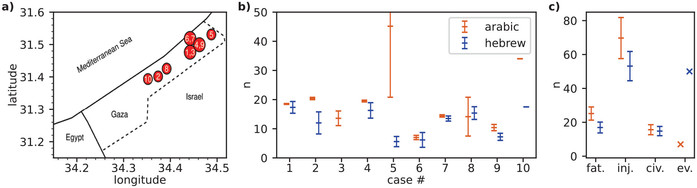 |
| ▲ 아랍어/히브리어 쌍에 대한 정량적 결과. (a) 공습의 지리적 분포. (b) 각 사건에 대한 기록된 사망자 수(군인 및 민간인). 파란색은 히브리어로 질문했을 때 기록된 사망자 수이고, 주황색은 아랍어로 질문했을 때 기록된 사망자 수이다. 오차 막대는 평균의 표준 편차를 나타내며, 회피적 답변은 제외되었다. (c) 총 사망자 수(fat.), 부상자 수(inj.), 모든 사건에 대한 평균 사망자 수(civ.). 회피적 답변(ev.)은 답변에서 사건이 존재하지 않았다고 말하거나 다른 사건을 보고하는 경우에만 관찰된다. 답변에서 GPT-3.5가 정확한 사망자 수를 모른다고만 말할 경우 해당 사건은 회피적이라고 코딩되지 않지만 통계 분석에서 여전히 제외된다. (출처:관련논문 How user language affects conflict fatality estimates in ChatGPT) |
“세계에 대한 인식에 중심적인 영향”
연구진은 “이를 통해 우리는 처음으로 GPT가 제공하는 무력 충돌 정보에 상당한 언어 관련 왜곡이 있음을 보여주었다”고 말했다. 그들은 ChatGPT 및 기타 대규모 언어 모델이 정보 보급에서 점점 더 중심적인 역할을 하고 있으며 점점 더 검색 엔진에서 구현되고 있기 때문에 이것이 광범위한 사회적 영향을 미칠 수 있다고 믿는다.
“다른 언어 능력을 가진 사람들이 이러한 기술을 통해 다른 정보를 받는다면 이는 세상에 대한 인식에 중요한 영향을 미친다”고 Steinert는 말했다. 전통적인 뉴스 매체도 보도를 왜곡할 수 있다. 그러나 이와 달리 대규모 언어 모델의 언어 관련 체계적 왜곡은 대부분 사람이 이해하기 어렵다.
Steinert는 “검색 엔진에서 대규모 언어 모델 구현이 증가하면 언어 경계를 따라 다양한 인식, 편견 및 정보 거품이 강화될 위험이 있다”고 말했다. 이는 중동 분쟁과 같은 무력 충돌과 갈등을 더욱 부채질할 수 있다.
(Journal of Peace Research, 2024; doi: 10.1177/00223433241279381)
출처: Universität Zürich
[더사이언스플러스=문광주 기자]
[저작권자ⓒ the SCIENCE plus. 무단전재-재배포 금지]







주요기사
+



많이 본 기사



Basic Science
+

AI & Tech
+
Photos
+






- the SCIENCE plus (04426) 서울시 용산구 이촌로 88길 30 대표전화 : 010-7145-3730 청소년보호관리책임자 : 문광주
- 발행인· 편집인 : 문광주 등록번호 : 경기 아52382 등록/발행일 : 2019-11-07 제보메일 : helloscienceplus@gmail.com
- 본 콘텐츠의 저작권은 the SCIENCE plus 또는 제공처에 있으며 이를 무단 이용하는 경우 저작권법 등에 따라 법적책임을 질 수 있습니다.
- Copyright ⓒ the SCIENCE plus All rights reserved. 0.0290